
在当今数据驱动的商业环境中,实时数据处理已成为企业获取竞争优势的关键,Apache Kafka Streams是一个功能强大的库,它允许开发者在Kafka集群上构建高性能、可扩展的流处理应用程序,通过利用Kafka Streams,开发者可以轻松地从多个数据源聚合数据,进行复杂的转换和聚合操作,并将结果推送到下游系统或存储到数据库中。
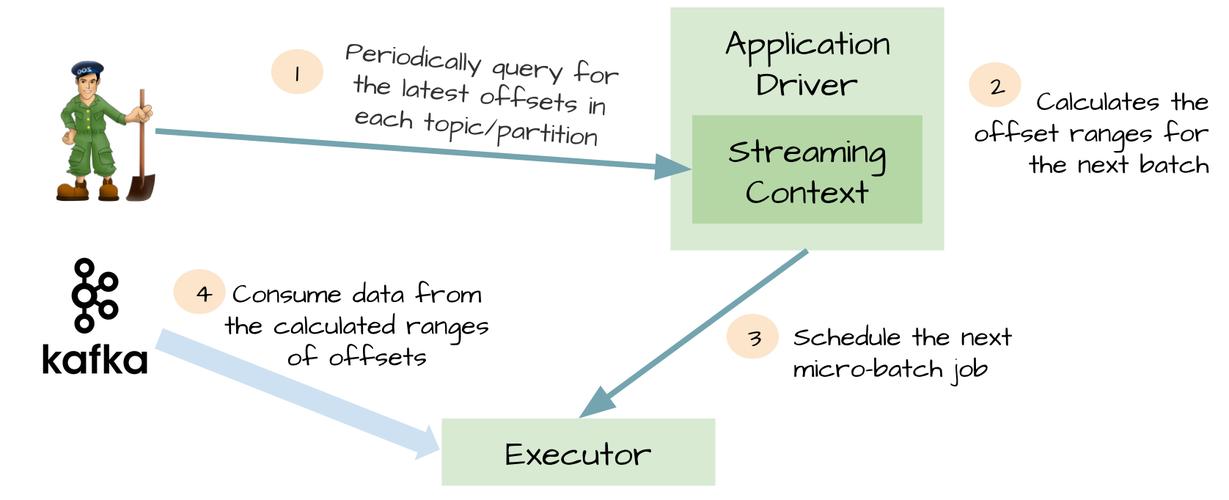

Kafka Streams简介
Kafka Streams是一个客户端库,它允许你在Stateful Stream Processing中使用Kafka集群作为数据存储,这意味着你可以构建能够处理来自一个或多个Kafka主题的数据流的应用,同时保持应用的状态信息,Kafka Streams提供了一种简单的高级抽象,使得编写分布式流处理任务变得像编写普通Java应用一样简单。
案例分析:没有后缀名的数据库与Kafka Streams的结合
场景描述
假设有一个在线购物平台,需要实时跟踪用户的浏览行为、购买行为以及商品库存情况,这个平台希望建立一个实时推荐系统,根据用户的实时行为动态调整推荐内容,为了实现这一目标,平台决定使用Kafka Streams来处理用户行为数据流和库存数据流,并将处理后的结果存储在一个没有后缀名的数据库中,如InfluxDB(虽然通常以.db结尾,但在某些配置中可以省略)。
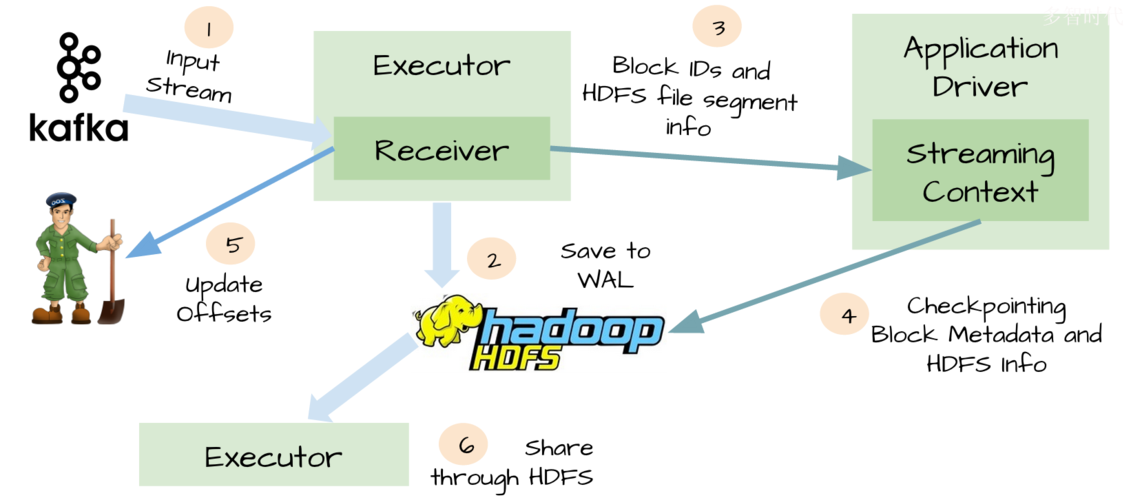
解决方案设计
1、数据收集: 将用户行为和库存更新发布到Kafka主题中。
2、数据处理: 使用Kafka Streams读取相关主题,对数据进行实时处理,计算商品的热度得分,根据用户最近的浏览行为更新用户画像等。
3、数据存储: 将处理后的数据写入InfluxDB,用于后续的查询和分析。
实施步骤
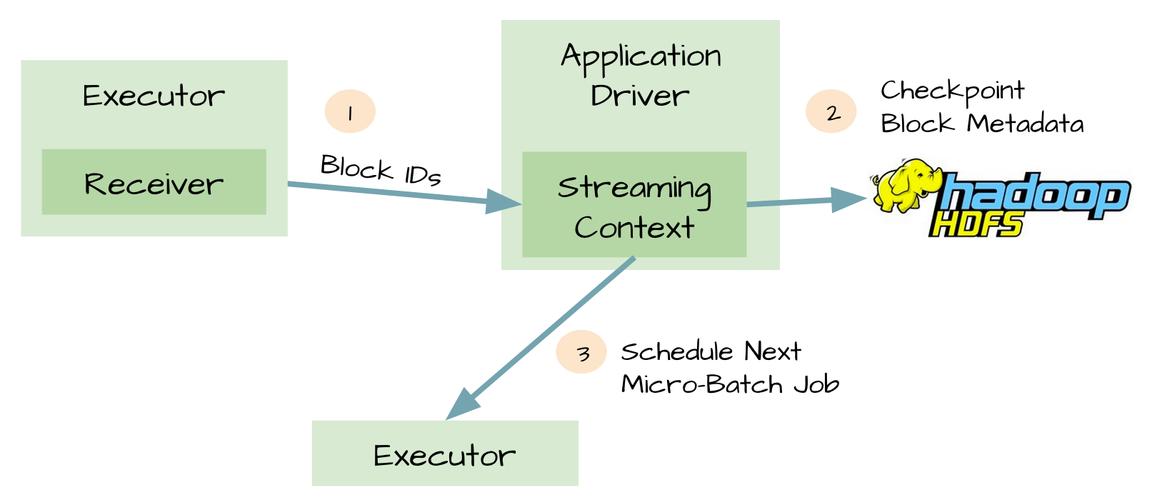
1、设置Kafka和Kafka Streams: 安装并配置Apache Kafka和Zookeeper,创建必要的主题。
2、编写Kafka Streams应用: 定义数据流的处理逻辑,包括数据的读取、转换、聚合和输出。
3、集成InfluxDB: 配置InfluxDB作为Kafka Streams的数据存储后端。
4、部署和监控: 将Kafka Streams应用部署到生产环境,并设置监控系统以跟踪其性能和状态。
预期结果
实时更新的用户画像和商品推荐列表,提升用户体验和销售转化率。
高效的数据处理流程,减少对传统数据库的依赖,提高系统的响应速度和扩展性。
相关问题与解答
Q1: Kafka Streams如何处理数据流中的故障恢复?
A1: Kafka Streams通过利用Kafka的记录持久性和复制特性来提供容错能力,当一个任务失败时,它可以从最近的提交点重新开始处理,保证至少一次的处理语义,Kafka Streams还支持精确一次(exactlyonce)处理语义,确保在出现故障时不会丢失或重复处理数据。
Q2: InfluxDB如何适应这种高吞吐量的数据写入需求?
A2: InfluxDB是为高速写入优化的时间序列数据库,非常适合存储大量的时间序列数据,通过批量写入和合理的数据保留策略,InfluxDB可以高效地处理来自Kafka Streams的高吞吐量数据流,InfluxDB的分布式模式支持水平扩展,可以根据数据量的增长灵活增加节点,满足不断增长的数据存储需求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复