
MapReduce在华为云中的应用


MapReduce是一种编程模型,用于处理和生成大数据集,该模型主要包括两个阶段:Map(映射)和Reduce(归约),Map阶段将输入数据分割成独立的数据块,然后由多个处理器并行处理;Reduce阶段则将Map阶段的输出整合起来,得到最终的结果,这种模型非常适合于分布式计算环境,因为它可以有效地利用集群中的资源来加速数据处理过程。
华为云MapReduce服务介绍
华为云提供了基于Hadoop的MapReduce服务,它允许用户在华为云上运行大数据处理任务,用户无需搭建和维护复杂的Hadoop集群,即可享受高效、可扩展的数据处理能力,以下是华为云MapReduce服务的一些关键特性:
易于使用:提供图形化界面和多种API,简化作业提交和管理。
弹性伸缩:根据作业需求自动调整计算资源。
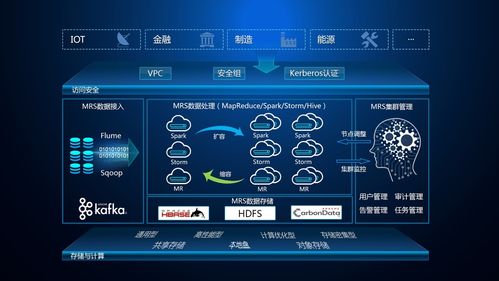
安全可靠:提供企业级的安全保护措施,确保数据安全。
高性能:优化的Hadoop发行版和高性能硬件支持,提高数据处理速度。
使用场景
华为云MapReduce适用于多种大数据处理场景,包括但不限于:
日志分析:处理大量日志文件,提取有价值的信息。

数据挖掘:从海量数据中发现模式和关联。
机器学习:对大规模数据集进行训练和预测。
生物信息学:基因序列分析等复杂计算任务。
操作指南
1、创建MapReduce作业:登录华为云控制台,选择MapReduce服务,点击“创建作业”按钮,填写作业名称和配置参数。
2、上传输入数据:将需要处理的数据上传到OBS(华为云对象存储服务)。
3、编写Map和Reduce函数:根据具体需求编写处理逻辑,可以使用Java、Python等语言。
4、提交作业:通过控制台或API提交作业,等待作业执行完成。
5、查看结果:作业完成后,可以在OBS中查看输出结果。
性能优化建议
合理设置Map和Reduce数量:根据任务特点和集群规模调整,以达到最优性能。
优化数据存储格式:使用SequenceFile、Parquet等高效的数据格式,减少读写开销。
压缩数据:对数据进行压缩,减少网络传输量。
合理分配资源:根据任务的资源需求,合理分配内存、CPU等资源。
相关问题与解答
Q1: 如何在华为云MapReduce中使用自定义JAR包?
A1: 在华为云MapReduce中,可以通过以下步骤使用自定义JAR包:
1、将包含Map和Reduce类的JAR文件上传到OBS。
2、创建MapReduce作业时,指定JAR文件在OBS中的路径作为“主类”参数。
3、在作业配置中指定Map和Reduce类的名称。
4、提交作业并监控执行状态。
Q2: 如何处理MapReduce作业失败的情况?
A2: 当MapReduce作业失败时,可以采取以下措施:
1、检查作业日志,确定失败原因。
2、根据错误信息调整代码或作业配置。
3、如果问题是由于资源不足导致的,可以考虑增加集群的资源配额。
4、重新提交作业,并密切关注执行过程中的任何异常。
通过这些措施,可以有效地解决问题并确保作业顺利完成。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复