
服务类项目抽取是自然语言处理(NLP)中事件抽取任务的一个子领域,旨在从文本数据中发现和识别与服务相关的事件信息,在服务行业中,事件抽取可以帮助企业更好地理解客户需求、优化服务流程、提升客户满意度以及制定有效的营销策略。

服务类项目抽取的dis_事件抽取详解
1. 定义与目的
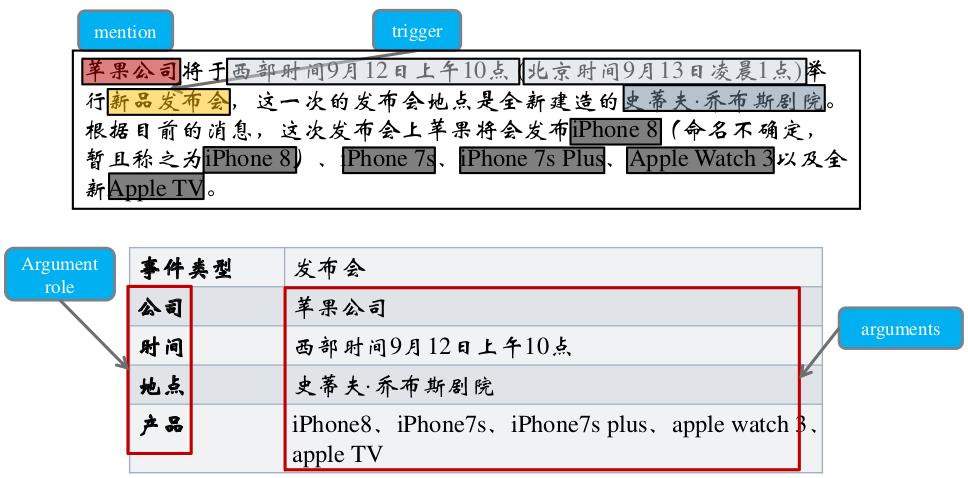
服务类项目抽取涉及从用户评论、咨询对话或服务记录等文本中提取关于服务的特定事件,例如预约、投诉、评价等,目的是通过自动化的方式快速获取这些信息,从而为服务提供者带来决策支持和操作效率的提升。
2. 关键步骤
事件抽取通常包括以下几个关键步骤:
文本预处理:清洗文本,去除无关信息,如特殊字符、停用词等。
实体识别:确定文本中的命名实体,比如时间、地点、人物和服务类型。
触发词识别:找到指示事件发生的关键词,如“预约”、“取消”或“投诉”。
事件分类:根据触发词和上下文将事件归类到预定义的类型中。
参数抽取:提取事件的相关属性,如事件发生的时间、涉及的服务或产品、相关人物等。
关系抽取:确定事件元素之间的关系,例如服务与客户之间的关系。
3. 技术方法
事件抽取可以采用不同的技术方法实现,包括:
规则基础方法:利用手工制定的规则来识别事件及其结构。
统计机器学习方法:使用特征工程和传统机器学习模型(如SVM、CRF)进行模式识别。
深度学习方法:应用神经网络模型,如CNN、RNN、BERT等,自动学习文本特征并进行事件抽取。
4. 应用场景
服务类项目抽取可以应用于多种场景,
客户服务分析:分析客户的咨询与反馈,改善服务质量。
市场调研:了解消费者对某项服务的态度和需求。
舆情监控:实时监控网络上对服务的评价和事件。
业务流程优化:基于事件数据调整和优化业务流程。
5. 挑战与趋势
尽管事件抽取技术不断进步,但仍面临一些挑战:
消歧义:同一词语在不同上下文中可能指向不同类型的事件。
隐含事件识别:有些事件在文本中没有明显的触发词。
跨领域适应性:模型需要适应不同领域的文本特点。
多语言处理:对于多语言文本的事件抽取能力。
未来的趋势包括更好的上下文理解、跨域适应性、少样本学习和领域自适应等。
表格示例
| 事件类型 | 触发词 | 相关实体 | 参数 |
| 预约 | 预定、预约 | 时间、服务 | 客户姓名、电话 |
| 投诉 | 投诉、不满 | 服务、问题 | 描述、请求 |
| 评价 | 好评、差评 | 等级、内容 | 服务类型、时间 |
相关问题与解答
Q1: 如何提高服务类项目抽取的准确性?
A1: 提高准确性可以通过以下方式:
使用更复杂的模型捕捉深层语义信息。
增加领域特定的预训练,使模型更好地理解服务行业的术语和语境。
引入人工校验和反馈机制,不断细化和完善抽取规则或模型。
Q2: 如何处理服务类项目抽取中的隐含事件?
A2: 处理隐含事件通常需要:
利用上下文信息和世界知识来辅助识别。
应用语义角色标注来揭示句子中各成分的关系。
结合用户行为数据和历史交互记录来推断可能的事件。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复