
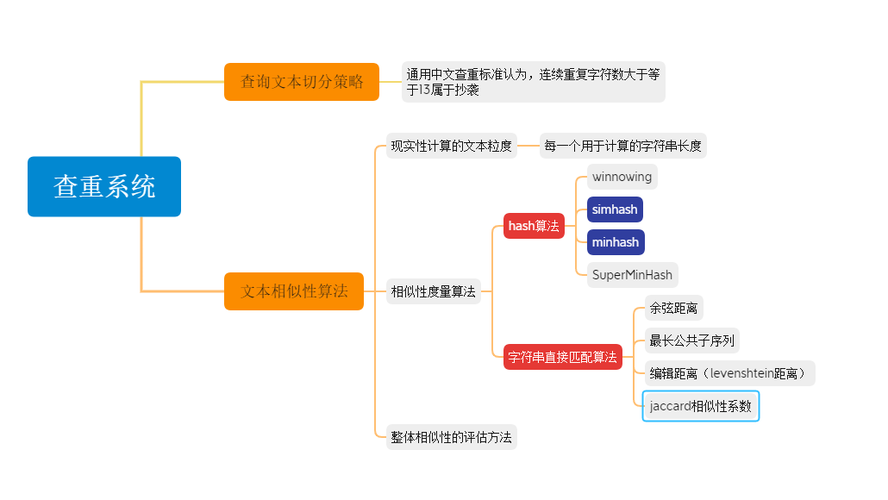
MATCH() 和 AGAINST() 函数来查询相似度。在数据库领域,相似度查询通常是指查找与给定数据点相似的其他数据点,对于MySQL等关系型数据库管理系统而言,处理文本相似度的常见做法包括使用全文索引、自然语言处理算法或者基于向量空间模型的方法。

全文索引
MySQL提供了全文索引功能,可以对文本内容进行索引并支持相似度搜索,全文索引适用于MyISAM和InnoDB存储引擎的CHAR,VARCHAR, 和TEXT类型的列,创建全文索引后,可以使用MATCH()...AGAINST()语法来执行相似度搜索。
假设有一个文章表articles,其结构如下:
| 字段名 | 类型 | 描述 |
| id | INT | 文章ID |
| title | VARCHAR | |
| content | TEXT |
可以对content字段添加全文索引:
ALTER TABLE articles ADD FULLTEXT(content);
然后使用MATCH()...AGAINST()进行相似度查询:
SELECT * FROM articles WHERE MATCH(content) AGAINST('关键词'); 自然语言处理
自然语言处理(NLP)技术可以用来分析文本内容,提取特征,并计算不同文档之间的相似度,这通常涉及到词干提取、停用词去除、词袋模型或TFIDF向量化等步骤。
在MySQL中,可以通过自定义函数来实现一些简单的NLP处理,但对于复杂的NLP任务,可能需要借助外部工具或服务。
向量空间模型
另一种方法是将文本转换为向量,并使用余弦相似度等度量来计算两个向量之间的相似度,这种方法通常需要将文本转换为词频向量或TFIDF向量,然后计算向量之间的距离。

在实际应用中,可以将文本预处理后的结果存储到数据库中,然后通过计算余弦相似度来找出相似的文章。
相关问题与解答
Q1: 如何在MySQL中实现基于TFIDF的文章相似度查询?
A1: 在MySQL中实现基于TFIDF的文章相似度查询需要以下步骤:
1、对文章内容进行分词,并计算每个词的TFIDF值。
2、将每篇文章表示为一个TFIDF向量。
3、将向量存储在数据库中,或者实时计算向量。
4、使用余弦相似度公式计算两篇文章的相似度。
由于MySQL本身不直接支持TFIDF计算,因此可能需要借助外部脚本或程序来实现这一过程,并将结果存储在数据库中供查询使用。
Q2: 全文索引和基于向量空间模型的方法在性能和准确性方面有何不同?
A2: 全文索引和基于向量空间模型的方法在性能和准确性方面有以下不同:
全文索引通常具有更好的性能,因为它是专门为文本搜索优化的,并且可以直接利用数据库的内置功能,它可能不如基于向量空间模型的方法准确,因为它不考虑词语的重要性和上下文信息。
基于向量空间模型的方法可以提供更高的准确性,因为它考虑了词语的重要性和上下文信息,这种方法的性能可能会较差,因为需要额外的计算和存储资源来处理和比较向量。
在选择方法时,需要根据具体应用的需求和资源限制来权衡性能和准确性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复