
分布式缓存服务器设计原理与设置
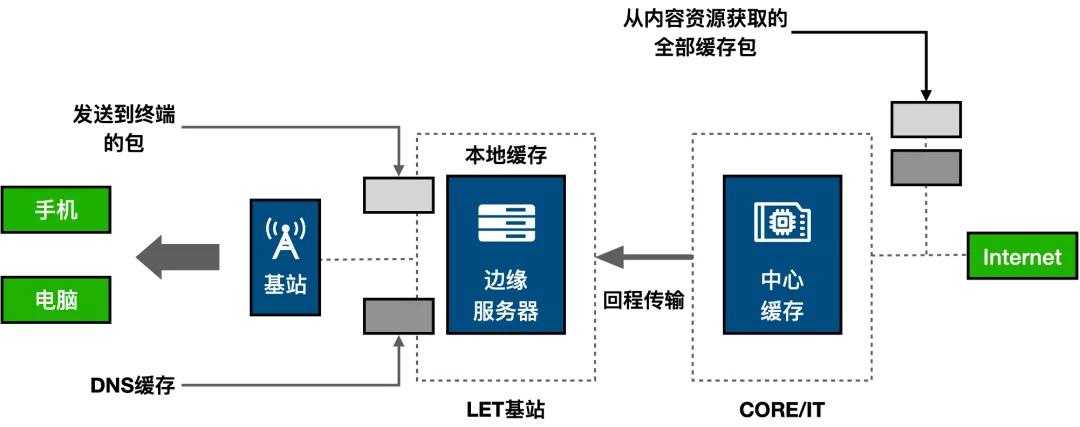

在当今的计算环境中,分布式系统已成为处理大规模数据和高并发请求的标准解决方案,分布式缓存作为提升系统性能的关键技术之一,其设计和实现尤为重要,本文旨在详细解析分布式缓存服务器的设计原理及设置方法。
1. 数据分布机制
一致性哈希算法
一致性哈希算法是分布式缓存中数据分布的核心机制,它解决了传统哈希算法在服务器数量变化时导致的大量数据重定位问题。
构建服务器节点环:假设有n台服务器,计算这n台服务器的IP地址的哈希值,把这些哈希值从小到大按顺时针排列,形成一个“服务器节点环”。
数据存储与获取:当客户端需要存储一个键值对时,先计算键的哈希值,并将其映射到环上的相应位置,该键值对将存储在该位置顺时针方向的第一个服务器上,这种机制保证了数据的均匀分布和高效的存取。
2. 缓存策略
缓存策略是提高缓存效率的关键因素,根据不同的需求场景,可以采用以下几种常见的缓存策略:
LRU(最近最少使用):淘汰最长时间未被使用的数据。
LFU(最少使用频率):淘汰一定时间段内使用次数最少的数据。
FIFO(先进先出):按照数据存入的顺序进行淘汰。
3. 缓存同步与一致性
在分布式环境下,保持各个节点缓存数据的一致性是一个挑战,通常采用以下方法来确保数据的一致性:
被动失效:当数据在源数据库中更新后,通过某种机制(如消息队列)通知所有缓存节点失效相应的缓存条目。
主动更新:除了在源数据变更时更新缓存外,还定期或基于某些条件预更新缓存,减少数据不一致的时间窗口。
4. 容错与恢复
为保证系统的高可用性,分布式缓存设计中必须考虑容错与恢复机制:
副本策略:每个缓存数据在多个节点上保留副本,即使部分节点失败,系统仍可正常运行。
快速失败转移:检测到节点故障时,能迅速将负载切换到健康节点,避免服务中断。
5. 扩展性考量
考虑到业务的快速增长,分布式缓存系统应设计为易于水平扩展:
动态增减节点:支持在不停机的情况下增加或减少缓存节点,以适应业务需求的变化。
自动负载均衡:系统应能自动识别新加入的节点,并重新分配数据,以达到新的负载均衡状态。
6. 监控与优化
持续的性能监控与优化对于维护一个健康的分布式缓存系统至关重要:
实时监控:监控系统的响应时间、命中率、网络流量等关键指标。
性能调优:根据监控数据调整配置参数,如内存大小、线程池设置等,以优化系统性能。
7. 相关数据
考虑到用户可能对分布式缓存的具体应用场景感兴趣,以下是一些相关数据:
命中率:一个高性能的分布式缓存系统的命中率通常在90%以上。
延迟降低:引入缓存后,系统的响应时间可以降低至原来的1/10或更低。
吞吐量提升:通过缓存处理的数据量可以达到直接访问数据库的数倍至数十倍。
可以看到分布式缓存服务器设计的复杂性和重要性,通过合理的设计和配置,可以极大地提升系统的性能和稳定性,满足现代互联网服务的需求。
8. 问题解答
8.1 如何选择合适的缓存策略?
答:选择缓存策略时应考虑应用的访问模式和数据特性,如果数据具有明显的访问热点,可以选择LFU策略;而对于数据访问较为均匀的情况,LRU可能是更好的选择。
8.2 分布式缓存中的热点问题如何解决?
答:热点问题指的是某些数据项被频繁访问,可能导致单个缓存节点过载,解决这一问题的策略包括复制热点数据到多个节点、使用专门的热点队列等,以分散请求压力。
通过以上深入分析,我们了解到分布式缓存服务器设计需要考虑数据分布、缓存策略、同步与一致性、容错与恢复、扩展性和监控等多方面因素,每一个环节都是确保系统高效运行的关键。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复