
传感框架的分库分表实践
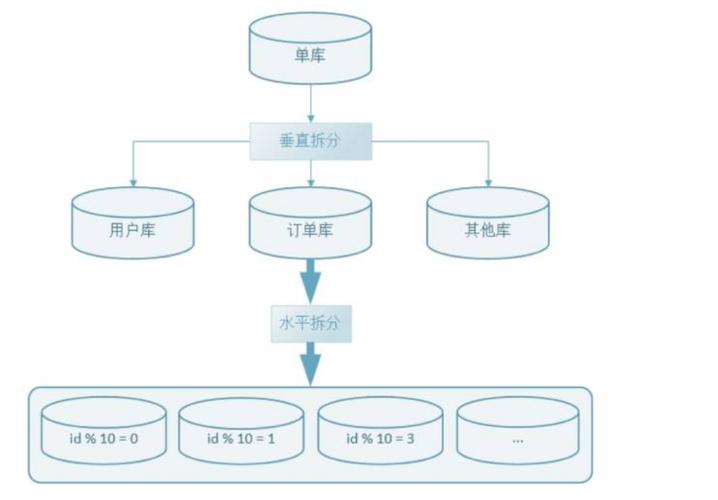

在现代的大数据应用中,随着数据量的不断增长,单个数据库的处理能力往往无法满足需求,分库分表成为了一个有效的解决方案,它通过将数据分散存储到多个数据库或表中来提高查询效率和数据管理的性能,本文将重点讨论在传感框架中实施分库分表的具体做法。
分库分表的基本概念
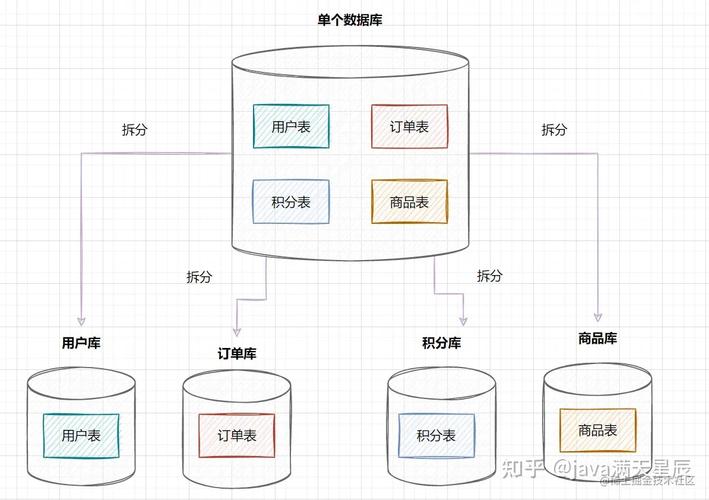
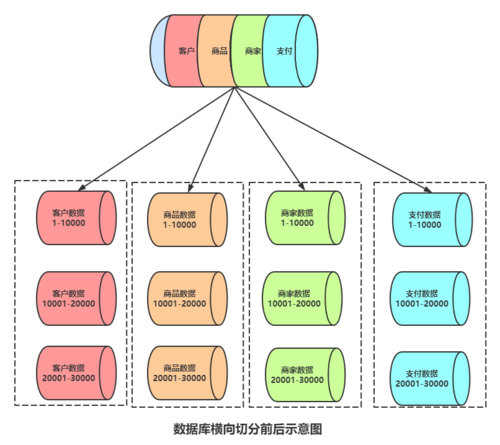
分库是将不同的数据表存储在不同的数据库中,而分表则是将一张大表按照一定的规则拆分成多张小表,这两种方法可以单独使用,也可以结合使用。
传感框架中的分库分表策略
1. 确定分库分表的维度
在传感框架中,通常根据传感器的类型、地理位置或者数据采集的时间等维度来决定如何进行分库分表。
按传感器类型分库:不同类型的传感器数据存储在不同的数据库中。
按地理位置分表:同一个地区的所有传感器数据存储在同一张表中。
按时间分表:按照数据采集的时间(如月份、季度)将数据存储在不同的表中。
2. 设计表结构
考虑到数据的查询效率和未来的扩展性,表结构的设计应该尽量简洁并且高效,可以使用如下的表结构:
| 字段名 | 类型 | 描述 |
| id | int | 主键,自增长 |
| sensor_type | varchar(50) | 传感器类型 |
| location | varchar(100) | 地理位置 |
| data | text | 采集的数据 |
| collection_time | datetime | 数据采集时间 |
3. 实现数据的分布存储
利用中间件或数据库代理来实现数据的自动分库分表,这需要配置相应的路由规则,确保数据能够按照既定的策略被正确分配。
4. 优化查询性能
索引优化:为常用的查询字段建立索引,减少查询时间。
读写分离:将读操作和写操作分别在不同的服务器上执行,提升系统的整体性能。
缓存机制:引入缓存机制,减少对数据库的直接访问。
5. 确保数据一致性和高可用性
在分库分表的环境中,保证数据的一致性和系统的高可用性是至关重要的,可以通过以下方式实现:
事务管理:确保跨库操作的原子性。
备份与恢复:定期备份数据,并确保能够快速恢复。
故障转移:建立故障转移机制,当某个节点发生故障时能迅速切换到备用节点。
分库分表的监控与维护
为了确保分库分表系统的稳定性,需要对其进行持续的监控和维护,包括但不限于:
性能监控:监控数据库的响应时间和吞吐量。
空间监控:监控数据库的存储空间使用情况,及时扩容。
日志分析:分析数据库的操作日志,及时发现并解决问题。
相关的问题与解答
Q1: 分库分表后如何保证联合查询的效率?
A1: 分库分表后的联合查询效率确实会受到影响,一种解决办法是在应用层进行多次查询然后将结果合并,另一种是使用数据库的联邦查询功能,但这要求所有参与的数据库都能够被同一个查询计划器访问和管理,还可以考虑使用数据仓库技术,定期将数据汇总后提供高效的查询服务。
Q2: 如何处理跨库事务?
A2: 跨库事务处理起来比较复杂,因为涉及到不同数据库之间的协调,一种常见的做法是使用分布式事务管理器,比如XA协议支持的两阶段提交,也可以通过业务层面的设计来避免跨库事务,例如确保事务只在单个数据库内完成。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复