
在大数据处理领域,MapReduce是一个广泛使用的编程模型,它由Google提出并被许多其他技术采用和实现,MapReduce的核心思想是将大规模数据处理任务分解成两个阶段:Map(映射)阶段和Reduce(归约)阶段,这种模型非常适合于并行处理大量数据,因为它可以在多个计算节点上同时进行数据的处理。
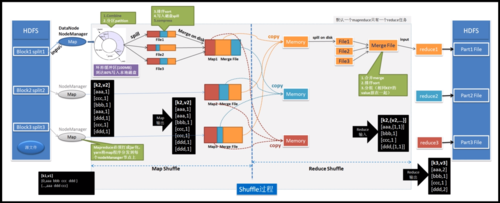

MapReduce 的基本概念
Map阶段:此阶段的任务是将输入数据分成小块,然后对每一块进行处理,生成键值对(key/value)作为中间结果,每个Map任务通常只处理输入数据的一个子集。
Reduce阶段:此阶段的任务是对Map阶段产生的中间结果按照键(key)进行聚合,并对每个键对应的一组值(values)进行处理,最终产生输出结果。
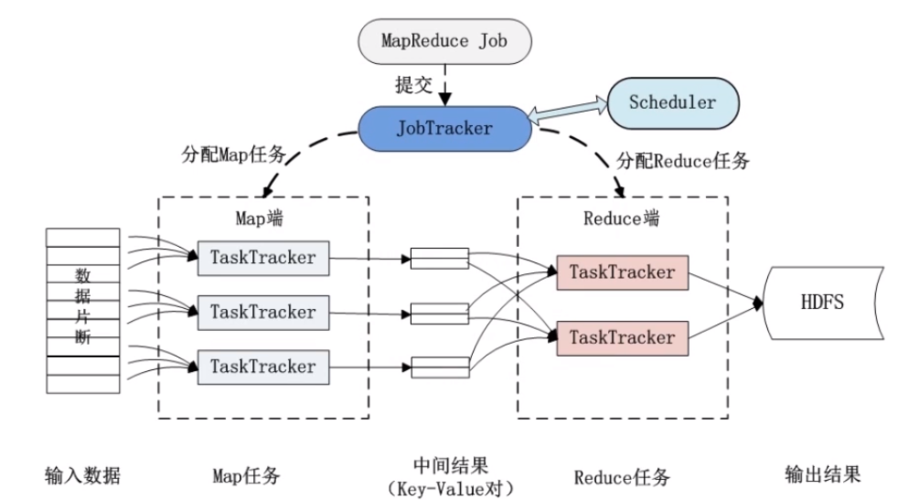
MapReduce 的工作流程
1、输入分片(Input splitting):输入数据被切分成若干个数据块,每个数据块由一个Map任务处理。
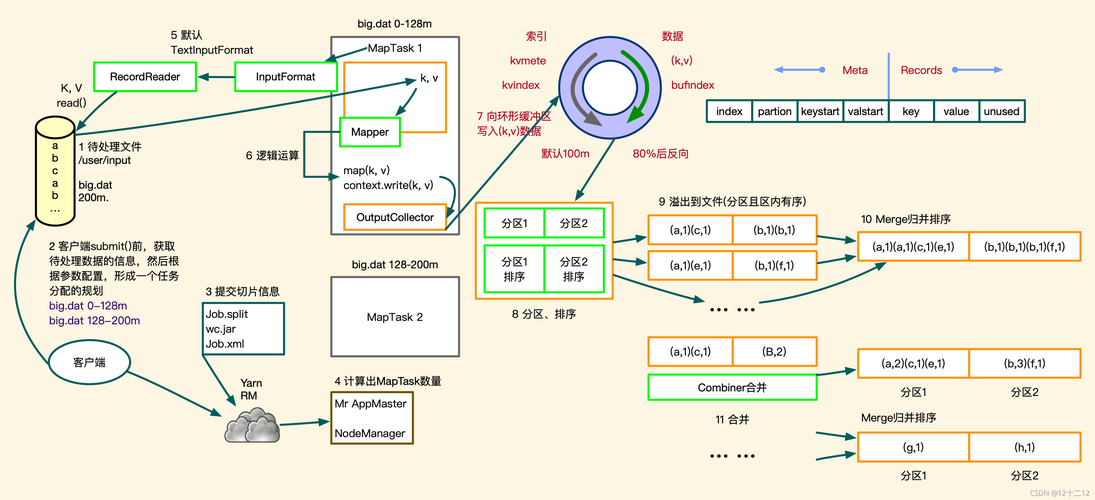
2、Map任务执行:每个Map任务读取其分配的数据块,执行用户定义的Map函数,生成中间键值对。
3、Shuffle and Sort:Map阶段的输出需要经过排序和分组,以确保具有相同键的所有值都发送到同一个Reduce任务。
4、Reduce任务执行:Reduce任务接收到所有相关数据后,执行用户定义的Reduce函数,输出最终结果。
5、Output:Reduce任务的输出是最终的处理结果,通常写入文件系统。
MapReduce 的优势和挑战
优势
可扩展性:通过增加更多的计算节点来处理更大的数据集。
容错性:单个节点故障不会影响整体任务的完成。
简化编程:开发者只需关注Map和Reduce函数的实现。
挑战
性能瓶颈:如果Reduce阶段处理不当,可能成为整个作业的性能瓶颈。
实时处理不足:MapReduce适合批量处理,对于需要快速响应的实时处理不够理想。
资源利用:在任务间可能存在资源利用不均的情况,如Map任务完成后,Reduce任务还未开始。
相关问题与解答
Q1: MapReduce如何处理大文件?
A1: MapReduce将大文件分割成多个小数据块,每个数据块由一个Map任务独立处理,这些小数据块的大小和数量取决于具体的实现和配置,在Hadoop中,默认的数据块大小通常是64MB或128MB。
Q2: 如何优化MapReduce作业的执行效率?
A2: 优化MapReduce作业的效率可以从以下几个方面考虑:
合理设置Map和Reduce任务的数量:根据集群的资源情况和作业的特性调整任务数量。
优化数据序列化和压缩方法:减少数据在网络中的传输量。
使用Combiner/InMap Reduce:在Map阶段就地进行部分聚合,以减少数据传输。
合理配置内存和磁盘缓冲区:提高I/O效率和数据处理速度。
代码优化:确保Map和Reduce函数高效执行,避免不必要的计算和数据操作。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复