
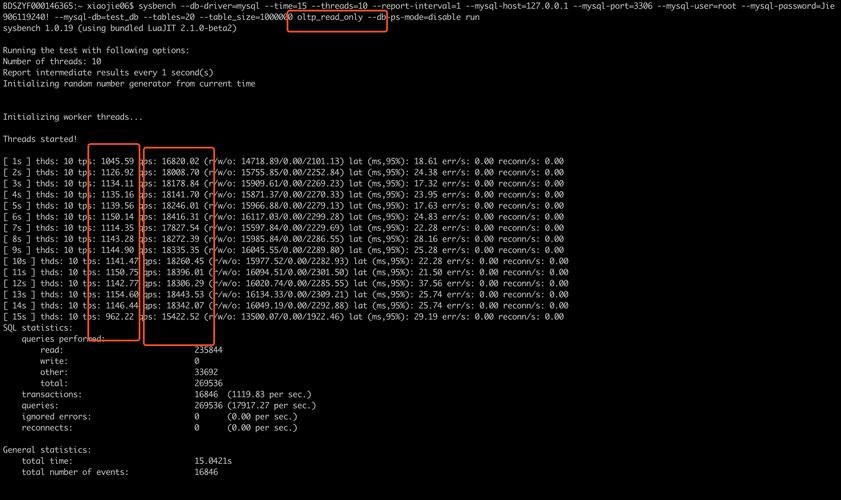
在讨论“mysql测试数据_RDS for MySQL 5.6测试数据”这一主题时,我们首先需要了解RDS(Relational Database Service)是什么以及MySQL 5.6版本的特点,我们将探讨如何为这种数据库服务准备测试数据。

RDS for MySQL 5.6简介
RDS是由亚马逊提供的一种托管的关系型数据库服务,它支持多种关系型数据库引擎,其中包括MySQL,用户无需管理底层的硬件或进行复杂的配置,就可以轻松地部署、操作和扩展数据库,MySQL 5.6是MySQL数据库管理系统的一个较老版本,它提供了一些新的功能和改进,比如全文搜索的改进、优化器的改变、复制的增强等。
准备测试数据
准备测试数据是一个关键步骤,因为它将直接影响到性能测试的准确性,以下是一些创建测试数据的步骤:
1. 确定数据模型
实体: 确定你的数据库中将包含哪些实体,例如用户、订单、产品等。
属性: 定义每个实体的属性,如用户有姓名、邮箱、密码等。
关系: 明确实体间的关系,如用户和订单是一对多关系。
2. 设计数据集
大小: 根据实际应用场景决定数据量的大小。
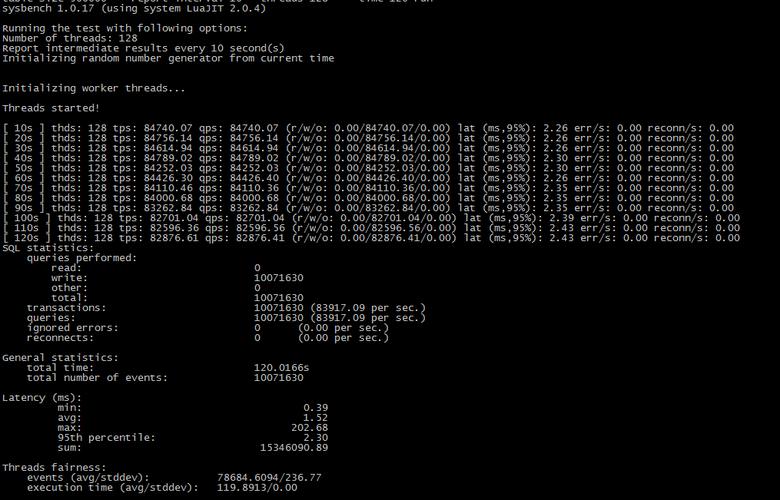
分布: 数据应遵循一定的分布模式,如均匀分布、正态分布等。
多样性: 引入足够的数据多样性以模拟真实世界情况。
3. 生成测试数据
手动创建: 对于小规模的数据,可以手动编写SQL插入语句。
自动化工具: 使用DBUnit、Mockaroo、GenerateData等工具自动生成大量测试数据。
数据脱敏: 如果使用生产数据作为测试数据,确保对敏感信息进行脱敏处理。
4. 导入数据
直接导入: 通过LOAD DATA INFILE命令或其他数据库工具直接将数据文件导入到RDS实例中。
逐步插入: 对于大型数据集,可能需要分批次逐步插入数据以避免长时间锁定表。
5. 验证数据
完整性检查: 确保所有必要的数据都已正确导入。
关系一致性: 验证实体间的关系是否按照设计正确设置。
性能测试: 运行一些查询来验证数据导入后的性能表现。
相关问题与解答
Q1: 如何在不暴露敏感信息的情况下使用生产数据进行测试?
A1: 使用生产数据时,可以通过数据脱敏来避免暴露敏感信息,这包括替换或删除个人身份信息、财务信息等敏感字段,可以使用专门的脱敏工具,或者编写脚本来实现。
Q2: 如何确保生成的测试数据具有代表性?
A2: 确保测试数据的代表性,需要在生成数据时考虑真实世界中的数据模式和业务规则,可以通过分析现有的生产数据来确定常见的模式,并在测试数据中重现这些模式,确保测试数据覆盖了各种边界情况和异常场景。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复