
MapReduce Shuffle服务是Hadoop框架中至关重要的一环,它负责将Mapper的输出作为Reducer的输入进行数据传输,Shuffle过程的效率直接影响到整个MapReduce作业的性能,对Shuffle过程进行调优是提高作业执行效率的关键步骤。
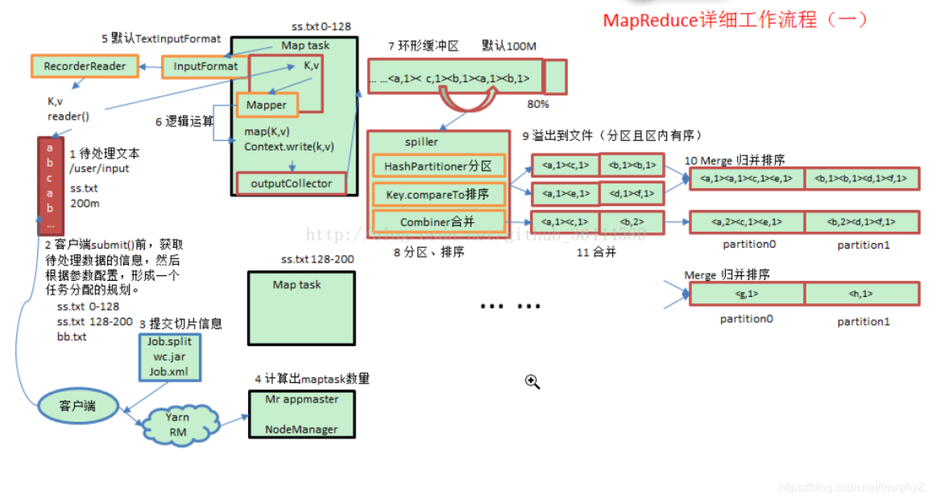

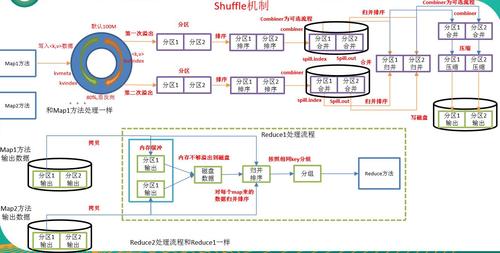
MapReduce Shuffle过程
在MapReduce框架中,Shuffle是指从Mapper的输出到Reducer的输入这一过程,它包括以下几个步骤:
1、分区(Partition): Mapper的输出会根据分区函数被划分到不同的Reducer。
2、排序(Sort): 输出的键值对按键进行排序。
3、压缩(Compress): 可选的步骤,对输出数据进行压缩以减少网络传输的数据量。
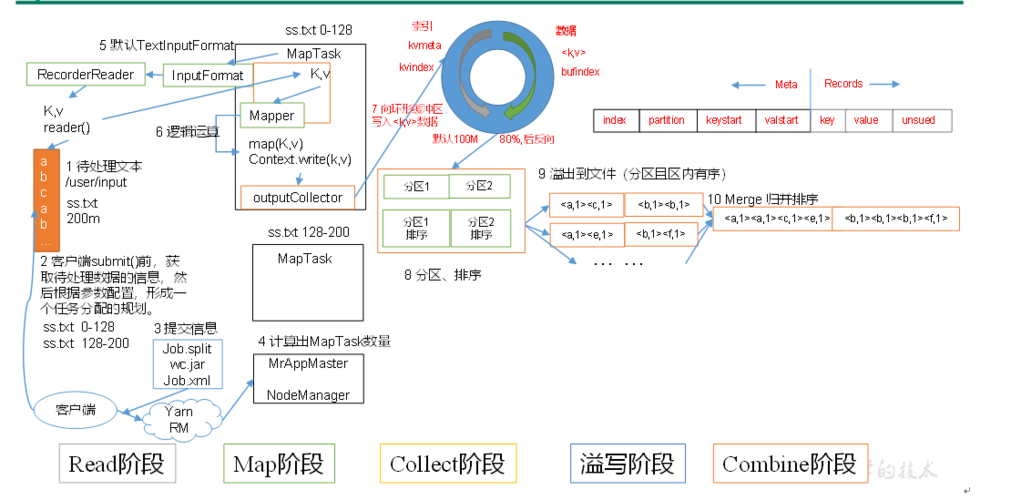
4、传输(Transfer): 把Mapper的输出通过网络传输到对应的Reducer节点。
Shuffle调优策略
1. 调整分区数量
增加Reducer的数量可以使得每个Reducer处理的数据量减少,从而可能减少处理时间,过多的Reducer也会导致管理开销增大,以及可能会产生大量的小文件影响后续处理。
2. 合理配置内存和缓冲区
内存配置: 调整JVM的堆大小,确保有足够的内存供Map和Reduce任务使用。
缓冲区大小: 调整Map端的输出缓冲区大小(mapreduce.map.output.buffersize),可以减少磁盘溢写次数,提高效率。
3. 使用压缩
开启Map输出和Reduce输出的压缩选项(mapreduce.output.fileoutputformat.compress 和mapreduce.output.fileoutputformat.compress.codec)可以减少网络传输和磁盘存储的数据量,但会增加CPU的使用率。
4. 优化排序机制
自定义Partitioner可以在不影响正确性的前提下,根据实际业务需求优化数据分布,减少数据传输量。
5. 调优网络带宽
在集群层面,确保网络带宽足够,避免成为瓶颈,可以通过升级硬件或优化网络配置来提升性能。
6. I/O优化
使用SSD等更快的存储介质可以减少I/O操作的时间消耗。
7. 合理设置Reducer启动时机
通过调整参数mapreduce.job.reduce.slowstart.completedmaps可以让Reducer稍晚一些启动,等待更多的Mapper完成,这样可以减少Reducer因等待数据而空闲的时间。
相关问题与解答
Q1: Shuffle过程中数据是如何从Mapper传输到Reducer的?
A1: 在Shuffle过程中,Mapper的输出会先写入到本地磁盘,然后根据分区函数分发到各个Reducer,Reducer通过HTTP从Mapper所在的节点拉取属于自己的数据分片,这个过程涉及到了数据的序列化、压缩和网络传输。
Q2: 如果Reducer数量设置得过多,会对MapReduce作业产生什么影响?
A2: 如果Reducer数量设置得过多,可能会导致以下影响:
每个Reducer处理的数据量变小,理论上可以加速数据处理速度,但也可能导致大量小文件的产生,影响后续的文件处理和存储效率。
过多的Reducer会增加任务调度的复杂性,可能导致集群资源分配不均,增加管理开销。
过多的并发任务可能会导致名字节点(NameNode)负载过高,影响整个集群的稳定性和性能。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复