
【Es框架需存储在hdfs_配置HDFS存储策略】
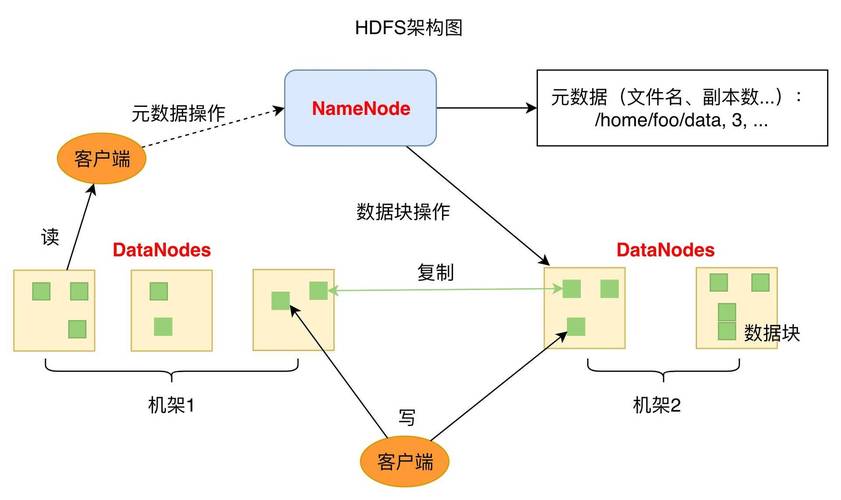

在大数据环境中,为了提高数据的可靠性和可扩展性,通常将数据存储在分布式文件系统(如HDFS)中,对于使用Elasticsearch(Es)框架进行数据存储和检索的场景,也需要将数据存储在HDFS中,本文将详细介绍如何配置HDFS存储策略以供Es框架使用。
1、安装和配置HDFS
需要安装和配置HDFS,以下是一个简单的步骤:
下载并解压HDFS安装包。
配置HDFS的核心配置文件hdfssite.xml,包括设置NameNode和DataNode的地址、副本数等参数。
启动HDFS集群。
2、创建Es索引
在HDFS中创建一个目录作为Es索引的根目录,可以使用以下命令:
“`
hadoop fs mkdir /es_index
“`
3、配置Es存储策略
在Es的配置文件elasticsearch.yml中,添加以下配置来指定HDFS作为存储策略:
“`yaml
index:
storage:
type: hdfs
location: hdfs://<namenode_address>:<port>/es_index
# 可选配置项
properties:
# 设置副本数,默认为1
replication: <replication_factor>
# 设置块大小,默认为128MB
blocksize: <block_size>
“`
<namenode_address>是HDFS NameNode的地址,<port>是NameNode的端口号,<replication_factor>是副本数,<block_size>是块大小,可以根据实际需求进行调整。
4、重启Es服务
修改完配置文件后,需要重启Es服务以使配置生效,可以使用以下命令:
“`
systemctl restart elasticsearch
“`
5、测试Es存储策略
完成上述配置后,可以验证Es是否成功使用了HDFS存储策略,可以通过以下步骤进行测试:
向HDFS中写入一些数据,使用以下命令创建一个文本文件:
“`
hadoop fs put /path/to/data.txt /es_index/data.txt
“`
使用Es的API或客户端工具向索引中添加文档,使用以下命令向索引中添加一个文档:
“`
curl XPOST ‘http://localhost:9200/es_index/doc/1’ d ‘{ "text": "Hello, Es!" }’
“`
查询索引中的文档,使用以下命令查询索引中的所有文档:
“`
curl XGET ‘http://localhost:9200/es_index/_search?pretty’
“`
如果能够成功执行以上操作,并且查询结果包含了之前写入的数据,则说明Es成功使用了HDFS存储策略。
6、监控和管理HDFS和Es集群
在实际应用中,需要定期监控和管理HDFS和Es集群以确保其正常运行,可以使用以下工具和方法进行监控和管理:
HDFS:使用Hadoop的管理工具,如Hadoop Web界面、Hadoop Command Line Interface(CLI)等进行集群状态监控、故障排查和性能调优。
Es:使用Es的管理工具,如Elasticsearch API、Kibana等进行集群状态监控、索引管理、性能分析和优化等操作。
7、高可用性和容错性考虑
在生产环境中,需要考虑HDFS和Es的高可用性和容错性,可以使用以下方法来实现:
HDFS:通过配置多个NameNode和DataNode来构建HA(高可用)模式的HDFS集群,确保至少有一个NameNode和一个DataNode处于活跃状态,以保证数据的持久性和可用性。
Es:通过配置多个节点来构建集群,并使用副本机制来保证数据的可靠性和容错性,可以使用分片和复制功能来提高集群的性能和可扩展性。
与本文相关的问题:
1、HDFS是什么?它有什么特点和优势?
答:HDFS(Hadoop Distributed File System)是一个分布式文件系统,由Apache Hadoop项目开发和维护,它的特点和优势包括:高可靠性、高吞吐量、可扩展性、容错性和低成本等,HDFS采用分布式架构,将大文件切分成多个块并分布在多台机器上进行存储和处理,以提高数据的可靠性和处理效率,HDFS还提供了丰富的API和工具,方便用户进行数据管理和分析。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复