
sql,SELECT 字段名, COUNT(字段名) as 计数,FROM 表名,GROUP BY 字段名,HAVING 计数 > 1;,`,,请将字段名和表名`替换为实际的字段名和表名。在数据库管理中,处理重复数据是一个重要且常见的任务,尤其是在如MySQL这样的关系型数据库系统中,确保数据的唯一性对于维护数据完整性和优化性能至关重要,本文将详细探讨如何在MySQL中查询和处理重复数据,包括单字段和多字段的去重策略。
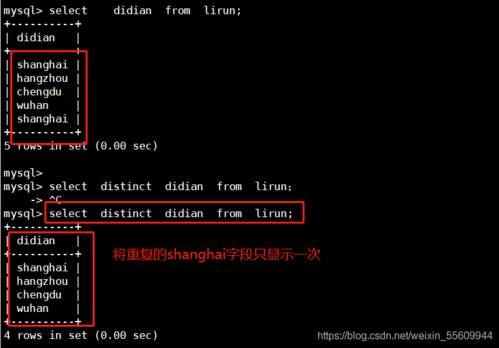

理解为什么会在数据库中出现重复数据,数据重复可能是由于数据导入过程中的错误、系统设计不当或缺乏有效的数据验证机制造成的,重复数据不仅浪费存储空间,还可能导致数据分析不准确,因此及时识别并清除这些重复项是非常必要的。
1. 创建索引防止数据重复
一个高效的方法是通过设置索引来预防数据重复,在MySQL中,可以将表中的某个字段设置为PRIMARY KEY(主键)或UNIQUE(唯一)索引,这样做可以保证该字段的值在整个表中是唯一的,尝试插入重复值将会被系统拒绝。
如果有一个users表,其中的email字段就应该设置为UNIQUE,以确保没有两个用户能使用相同的邮箱注册。
CREATE TABLE users (
id INT AUTO_INCREMENT,
email VARCHAR(255) UNIQUE,
name VARCHAR(100),
PRIMARY KEY(id)
); 2. 查询重复数据
要找出并处理重复数据,首先需要有能力查询到它们,使用GROUP BY和HAVING语句是一种常见方法,可以组合field1和field2,然后使用COUNT(*)函数来统计每个组合的数量,最后使用HAVING语句筛选出数量大于1的记录。
假设有一个orders表,其中customer_id和order_date可能会重复:
SELECT customer_id, order_date, COUNT(*) FROM orders GROUP BY customer_id, order_date HAVING COUNT(*) > 1;
3. 删除重复数据
查询到重复数据后,下一个步骤通常是删除它们,这应该非常谨慎地进行,以免误删重要数据,一种安全的方法是只删除重复记录中的额外条目,保留一条记录,可以通过给每组重复记录添加一个序号,然后删除除第一条之外的所有记录来实现这一点。
为了从orders表中删除重复订单,可以按customer_id和order_date进行分组,然后根据这两个字段的联合排序,仅保留每组的第一条记录。
DELETE FROM orders WHERE (customer_id, order_date, id) NOT IN ( SELECT customer_id, order_date, MIN(id) FROM orders GROUP BY customer_id, order_date );
4. 多字段去重
对于更复杂的情况,可能需要基于多个字段来识别和去除重复记录,这实际上是单字段去重的衍生,原理是将多字段数据合并为单一字段,再进行去重处理,可以使用子查询,并通过GROUP BY和HAVING筛选出重复项,最后使用min或max函数获取最小或最大ID的记录进行删除。
5. 数据去重的注意事项
处理MySQL数据库中的重复数据通常涉及查询、确认和删除三个步骤,在操作前,必须备份数据以防万一,并且应在非高峰时段执行清理过程,以避免影响正常业务。
处理MySQL中的重复数据是一项细致的工作,需要对数据结构和业务逻辑有深入了解,正确设置索引可以有效防止未来的数据重复问题,一旦发现重复数据,应通过详细的查询和谨慎的删除操作进行处理,确保数据的完整性和准确性。
相关问题与解答
Q1: 如果表中已经存在大量重复数据,如何安全地清理这些数据?
A1: 首先进行数据备份,使用GROUP BY和HAVING确定重复项,使用子查询选择要保留的数据(如具有最小或最大ID的记录),最后从表中删除不在保留列表中的记录,这个过程应在非业务高峰时间执行,以减少对系统性能的影响。
Q2: 是否可以使用自动化脚本定期检查和清理重复数据?
A2: 是的,可以编写自动化脚本来定期检查和清理重复数据,这通常涉及编写存储过程或定时任务,使用上述提到的查询和删除命令,自动化程度取决于数据变动的频率和系统的业务需求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复