
在计算机科学中,浮点数格式是用来存储和处理小数点数值的,其中包括float、double等类型。 浮点数的存储方式与整数截然不同,基于IEEE 754标准,该标准为浮点数的表示和存储提供了详细的规范。

存储格式的区别:
1、符号位(S): 在浮点数的表达中,最左侧的一位被保留作为符号位,如果该位为0,则数值为正;如果为1,则数值为负。
2、指数部分(E): 符号位之后的部分被用作指数,在float类型中,指数占据8位,使用二进制表示,并通过一个称为“偏移量”的特定值(对于float,该值为127)进行调整。
3、尾数部分(M): 在指数之后的是尾数部分,它定义了浮点数的有效数字,在float中,尾数部分包括23位,加上隐含的最高位“1”(这部分不直接存储,但默认存在),形成了总共24位的有效数字。
4、字节大小: float使用32位(即4个字节)进行存储,而double类型使用64位(8个字节),这两种类型的区别在于它们各自用于表示指数和尾数的位数不同,从而影响它们的精度和能表示的范围大小。
详细分析:
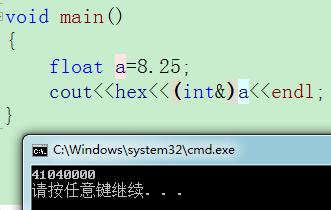
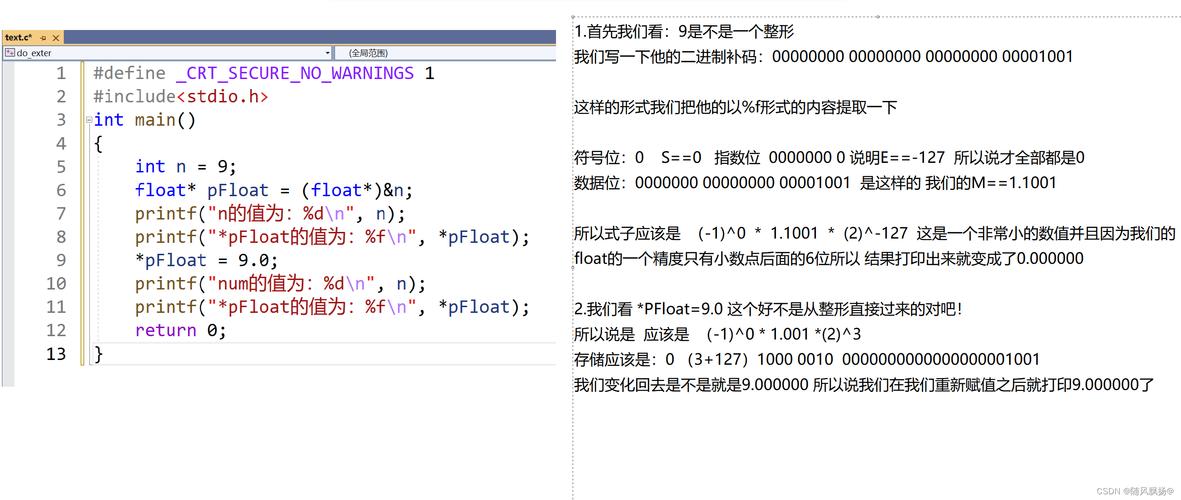
精度问题: 由于存储空间的限制,特别是尾数部分的位数限制,浮点数无法精确表示所有小数,当数字的有效数字超出所能表达的范围时,将会发生近似,这可能导致精度损失。
范围问题: 指数部分通过偏移量调整后能表示的范围大大扩展,但仍然存在上溢和下溢的问题,这意味着非常大或非常小的数可能无法准确表示。
以下是关于浮点数存储的两个问题的解答:
Q1: 为什么浮点数在计算中会出现精度问题?
Q1: 浮点数的精度问题主要源于其存储格式中尾数部分的位数限制,由于只有有限位来存储有效数字,当数值超出尾数能表达的范围时,会导致精度损失,在float中,只有大约7个十进制位是准确的,超过这个范围的数值将只能被近似存储。
Q2: float和double的主要区别是什么?
Q2: float和double的主要区别在于它们的存储空间不同,float使用32位存储,包括8位指数和23位尾数(加上隐含的“1”),而double使用64位,通常包括11位指数和52位尾数(同样有隐含的“1”),这使得double能提供更高的精度和更大的数值范围,适合对精度要求较高的计算。
通过以上分析,可以更深刻地理解浮点数在计算机科学中的应用及其相关的存储特性,这种格式不仅支持大量数据的操作,但也带来了精度和范围的限制,了解这些细节有助于在实际编程和应用中做出更合理的数据处理决策。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复