
在当前人工智能迅速发展的背景下,ModelArts Pro平台提供的文本分类功能成为了企业与开发者们广泛关注的焦点,小编将逐步探讨如何在ModelArts Pro平台上新建一个文本分类应用的详细步骤和注意事项。

1、进入ModelArts Pro平台
访问控制台:首先需要登录ModelArts Pro平台,通过点击左上角服务列表按钮,从下拉菜单中找到【人工智能】,再找到并点击【ModelArts pro】进行选择进入。
同意服务声明:在进入ModelArts Pro平台之前,用户需勾选并同意ModelArts服务声明,确保后续操作的合规性。
2、选择自然语言处理套件
定位工作流:进入平台后,选择自然语言处理套件,点击“进入套件”以便于进行下一步的操作。
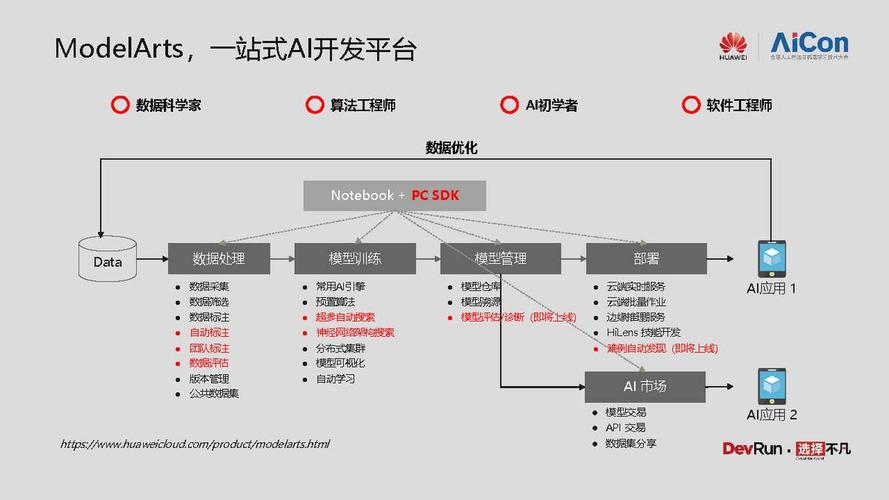
工作流选择:在应用开发工作台,应切换到“我的工作流”,其中可以选择通用文本分类工作流来开始一个新的项目。
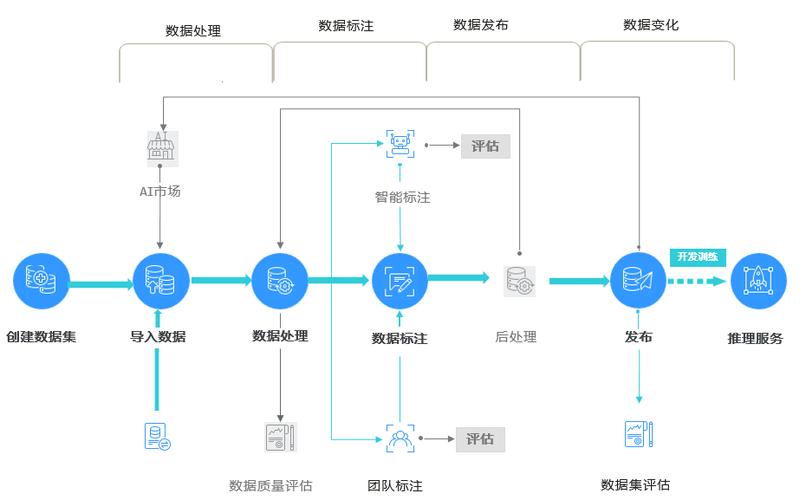
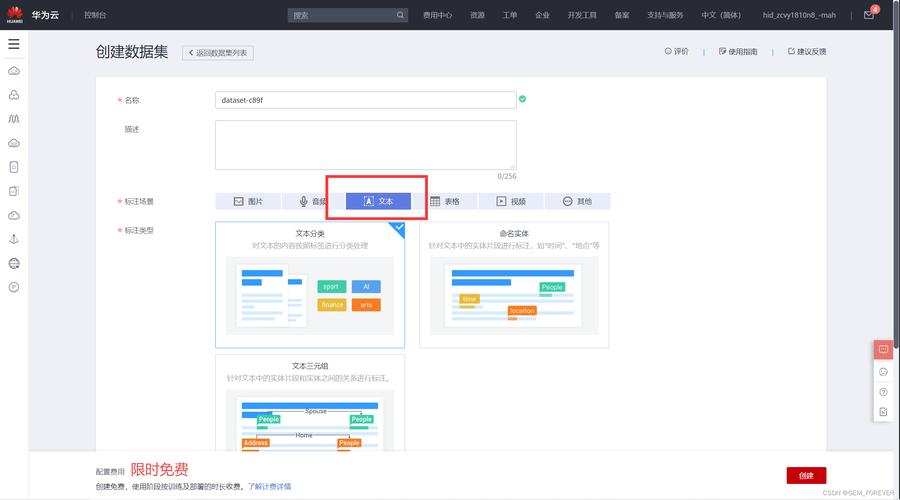
3、创建数据集
数据管理:在ModelArts平台中,点击“数据管理”然后选择“数据集”进行创建,这一步是文本分类基础,也是模型训练的数据来源。
导入标签:数据集创建时,需要将数据和标签分离,选择合适的位置导入标签,为后续的模型训练打下基础。
4、构建文本分类模型
利用工作流:ModelArts Pro提供了通用文本分类工作流和多语种文本分类工作流,用户可以根据实际需求选择相应的工作流来构建模型。
上传数据:通过工作流指引支持自主上传文本数据,这些数据将用于构建高精度的文本分类预测模型。
5、部署在线服务
模型部署:成功构建文本分类模型后,下一步便是将模型部署为在线服务,这样就可以通过网络对模型进行访问和使用。
测试服务:部署完成后,可以通过上传一段文本来分析其情感倾向或分类结果,从而验证模型的实用性和准确性。
深入理解以上每个步骤对于新建一个高效、准确的文本分类应用至关重要,以下将对一些特殊注意事项进行阐述:
确保在创建数据集时,数据的质量和多样性足以代表实际应用场景,这会直接影响模型的效果。
在选择工作流时,了解不同工作流的特点和适用场景可以更好地满足特定需求。
部署服务后的监控和管理同样重要,要定期检查服务状态并优化更新以保持服务的稳定和高效。
用户可以在ModelArts Pro平台上顺利新建一个文本分类应用,并通过一系列步骤实现模型的训练与部署,操作过程中需要注意数据准备的充分性、模型选择的适宜性以及服务部署后的稳定性管理,为了进一步帮助理解和操作,将提供相关问题与解答的栏目:
相关问题与解答
Q1: 如何确保文本分类模型的准确性?
A1: 确保文本分类模型的准确性需要从数据质量、模型选择和后期优化三个方面着手,输入的数据应具有高质量且代表性,覆盖各种可能的分类情况,选择适合的模型和参数调优也非常关键,根据实际应用反馈对模型进行迭代优化可以进一步提高准确性。
Q2: 部署在线服务后,如何进行有效的服务管理和监控?
A2: 部署在线服务后,有效的服务管理和监控包括设置合理的访问权限、监控系统性能指标、及时响应用户反馈等措施,采用自动化工具进行负载均衡和故障恢复也是必不可少的,以确保服务的稳定和可靠。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复