
快速购买Kafka流式集群
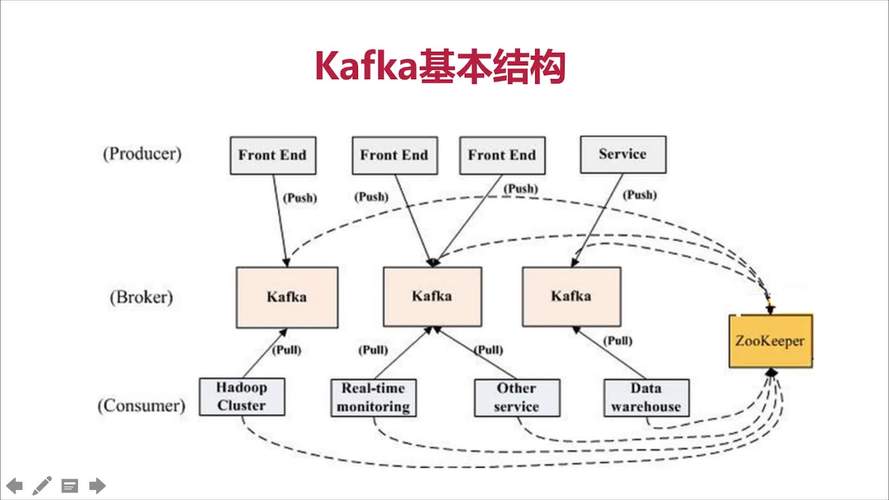

在大数据和实时数据处理的背景下,了解MapReduce分析集群与流式集群的差异并选择适合的集群配置至关重要,本回答旨在深入探讨两种集群的特性、优势及适用场景,并提供指导以帮助用户根据需求作出明智的购买决策。
分析集群特性
分析集群主要设计用于处理静态数据集,其核心优势在于能够高效地执行大规模数据的批处理任务,这种类型的集群适合于数据挖掘、日志分析等场景,其中数据不需要实时更新,而是按批次进行处理和分析。
节点构成: 分析集群主要由Master节点和分析Core节点组成,Master节点负责协调整个集群的任务调度和资源分配,而分析Core节点则承担实际的数据加工和计算任务。
数据处理模式: 传统的MapReduce模型中,任务被分为映射(Map)和归约(Reduce)两个阶段,分析集群优化了这一过程,使得对静态数据集的处理更为高效。
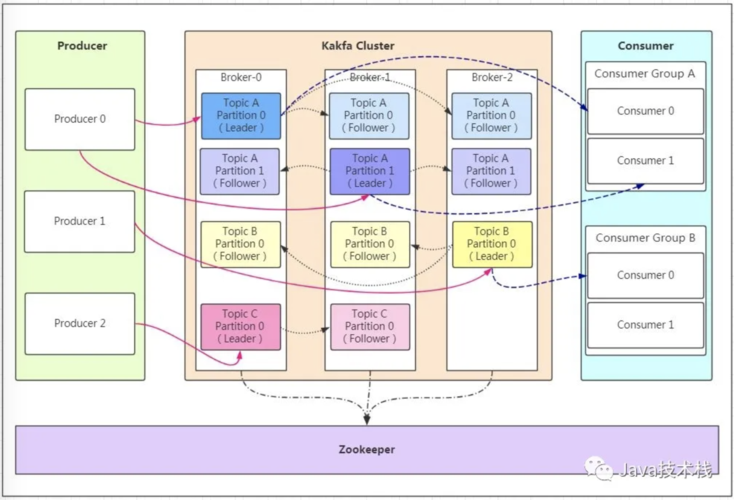
流式集群特性
相对于分析集群,流式集群是为了处理连续的数据流而设计的,它适用于需要实时处理的场景,如实时监控、实时推荐系统等。
节点构成: 流式集群包含Master节点和流式Core节点,Master节点的功能与分析集群类似,而流式Core节点则专门处理流式数据的快速、连续计算。
数据处理模式: 流式集群通常采用Pipeline模式,数据在不断流入的过程中即被处理,并及时输出结果,这要求极高的处理速度和较低的延迟。
比较与应用场景
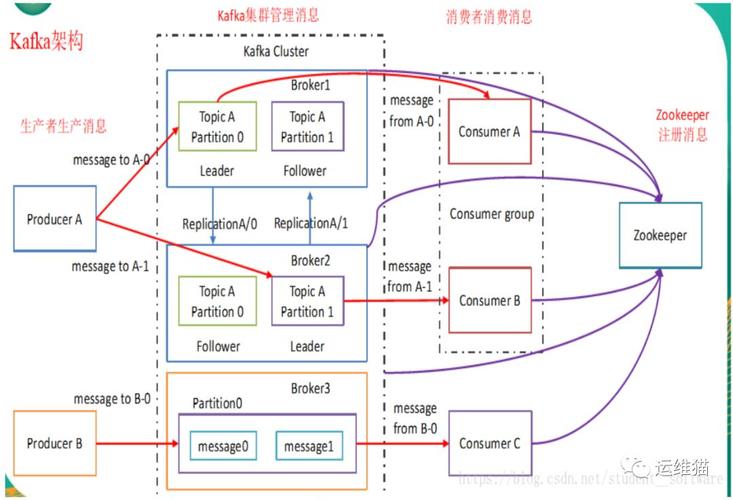
在选择集群类型时,考虑数据的动态性和处理需求是关键,分析集群适合于数据量庞大但相对固定的场合,而流式集群则应对高速度、持续更新的数据环境,混合集群提供了两者的部分优点,但在资源配置和管理上可能带来更高的复杂性。
购买和使用建议
1、需求评估: 根据数据处理的实时性要求和业务特性进行评估选择。
2、成本效益分析: 考虑到成本因素,分析集群通常更经济,而流式集群在硬件和运维上可能成本较高。
3、技术适配: 确保技术团队具备相应的维护和优化能力,特别是对于需要自定义配置的情况。
相关问题与解答
Q1: 如何确保所购集群满足未来业务增长的需求?
Q2: 在实际操作中如何优化集群性能?
A1: 考虑到业务增长,选择可扩展的集群配置是关键,定期的性能评估和资源调配也不可或缺。
A2: 优化集群性能可以从硬件升级、合理配置资源、优化数据存储和处理算法等方面着手,同时保持软件和系统的更新也是提高性能的有效方法。
归纳上述信息,用户在购买Kafka流式集群前应充分了解不同集群的特性及其适应的业务场景,通过对比分析,结合自身需求进行选择,可以最大化地发挥集群的性能,支持业务的高效运行。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复