
在当今的软件开发领域,分布式系统已经成为处理大规模数据和高并发请求的标准解决方案,分布式缓存作为提高系统性能和可伸缩性的关键技术之一,它允许暂存经常访问的数据,从而减少对后端数据库的依赖,并提升系统的响应速度和承载能力,序列化是将对象状态转换为字节流的过程,这对于在网络中传输数据或将其存储在缓存中至关重要,在分布式缓存中,序列化机制必须既高效又能够保证数据完整性,以确保系统的整体性能和稳定性,具体分析如下:

1、数据压缩:
数据压缩技术通过减少数据所占用的空间来优化存储和网络传输的成本,在分布式缓存中,有效的数据压缩可以显著降低资源消耗,特别是对于大型数据集和非结构化数据。
2、数据序列化:
序列化过程涉及将复杂数据结构如对象和数组转换成线性的字节序列,这种转换对于数据在网络传输或持久化前是必需的,在分布式系统中,一个高效的序列化机制能够提升数据传输速度并减少延迟。
3、Redis的特性:
Redis是一个开源的高性能keyvalue存储系统,常用于实现分布式缓存,它支持多种数据结构,如字符串、哈希、列表、集合、有序集合与二进制字符串等。
Redis使用ANSI C编写,以其出色的性能和易用性广受欢迎,它支持在内存中的数据持久化,确保数据的安全及快速恢复。
4、Spring Cache与Redis的集成:
Spring框架提供的Spring Cache模块简化了缓存逻辑的实现,使得开发者能够轻松地集成缓存解决方案,如Redis,到基于Spring的应用中。
5、分布式缓存的优势:
引入分布式缓存层能显著提升数据读取速度,并增强系统的扩展能力,通过缓存频繁访问的数据,可以减轻数据库的压力,从而改善整个应用的响应时间和吞吐量。
6、高并发的处理:
Redis等分布式缓存解决方案能够应对高并发的数据访问需求,支持多用户的高速数据操作,是大规模互联网服务架构中不可或缺的组件。
7、数据同步与一致性:
在分布式环境中,保持数据同步和一致性是一大挑战,利用如Redis Cluster等技术,可以实现数据自动分片及高可用性,确保数据在多个节点间的一致性。
8、容错与恢复:
分布式缓存系统需设计容错机制以应对节点故障,Redis的持久化功能(如RDB和AOF)为系统提供了数据恢复保障,减少数据丢失的风险。
分布式缓存在现代软件架构中发挥着越来越重要的作用,而Redis作为一个高性能的分布式缓存解决方案,其易于扩展、高性能及丰富的数据类型支持使其成为热门选择,理解分布式缓存中的序列化机制及其对系统性能的影响,以及如何有效地使用Redis来实现数据存储和访问加速,是优化分布式系统性能的关键。
提出的问题:
1、如何在分布式缓存中处理大对象的序列化和反序列化?
2、在分布式系统中,如何保证缓存数据的一致性和高可用性?
解答:
1、对于大对象的序列化和反序列化,可以选择更高效的序列化库如Kryo或Protobuf,这些库相较于Java自带的序列化机制可以提供更小的数据大小和更快的处理速度,还可以考虑将大对象拆分成多个小对象进行分别处理,以减少单个序列化操作的性能负担。
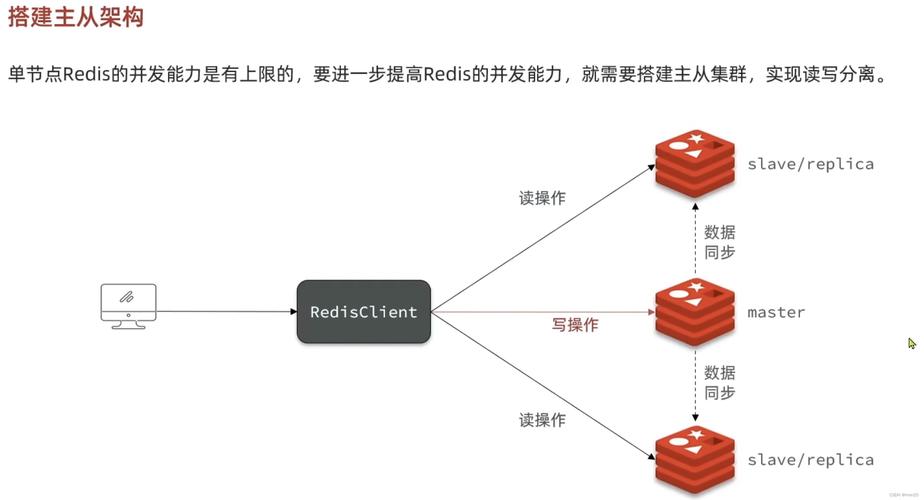
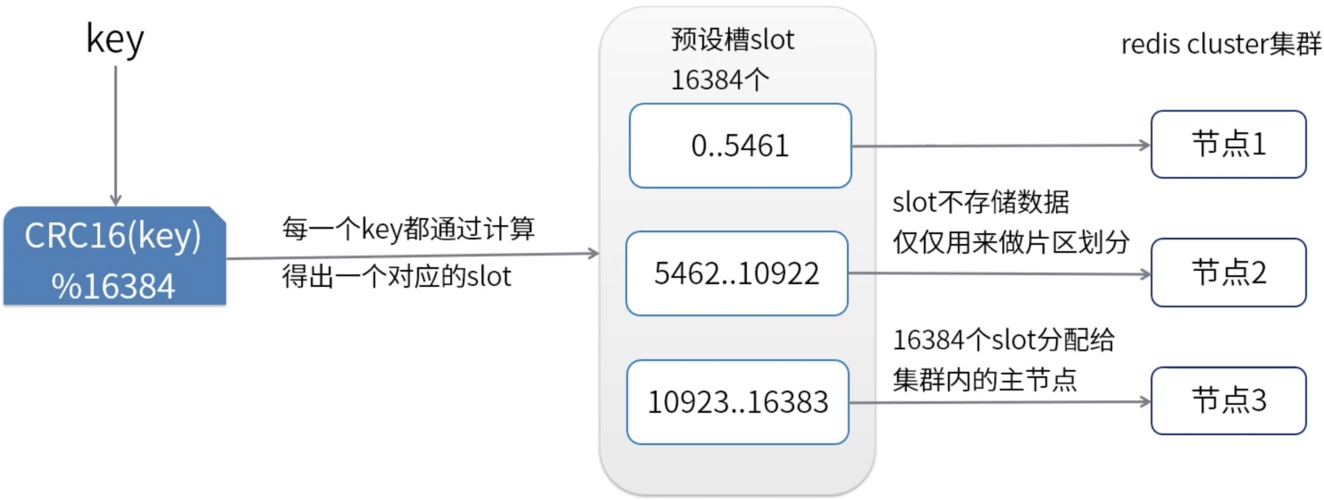
2、保证缓存数据的一致性和高可用性通常需要利用分布式缓存系统本身的机制,Redis提供了主从复制和哨兵机制来监控节点状态并实现自动故障转移,在更复杂的场景下,可以考虑使用Redis Cluster,它支持自动分片和数据复制,确保在节点故障时能够快速恢复并保持数据的一致性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复